Лучшая стратегия — та, которая решает задачи бизнеса. Если верно поставить цели и определиться с KPI, настроить рекламу будет проще.

Мы начинаем цикл статей на тему автоматизации разработки рекламных кампаний для интернет-магазина. Цикл статей рассчитан на продвинутых специалистов — банальностей не будет!
После прочтения статей вы научитесь: оптимизировать кампании в Excel методами, которые используются в оптимизаторах конверсий; автоматически собирать семантику, сегментировать и создавать объявления; прогнозировать конверсию на базе истории и многое другое.
Темы статей:
Материал сложный и раскрывает только базовые подходы к автоматизации, чтобы задать вам вектор развития.
Необходимый стек знаний для комфортного чтения: вы без труда можете составить кастомный отчет в Google Analytics и Метрике; парсили и фильтровали ядра в Key Collector; знаете, что такое средневзвешенная; пользуетесь сводными таблицами в Excel; знаете Python, Pandas либо имеете небольшой опыт программирования; знаете, почему в некоторых тематиках слова «кавычат», а в других нет
Итак, начнем! В данной статье мы выгрузим поисковые запросы с конверсиями из Яндекс Метрики, которые впоследствии будем расширять путем кластеризации, отфильтруем их и приведем к лемме. Так же мы выгрузим данные для расчета ставки из Google Analytics.
На текущем этапе сложно объяснить, как конкретно будут использоваться эти данные, но наберитесь терпения, постепенно к вам придет понимание.
Создаем новый запрос
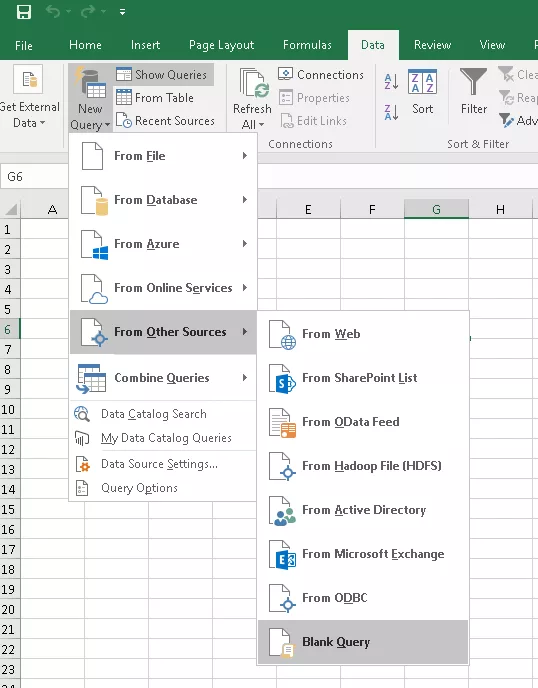
Переходим в режим редактирования
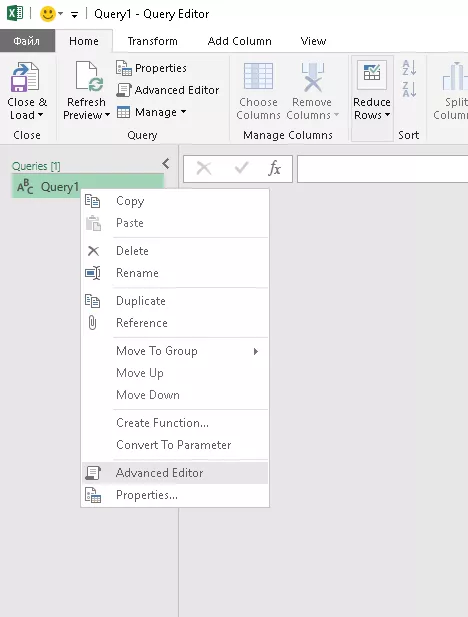
Вставляем код функции запроса
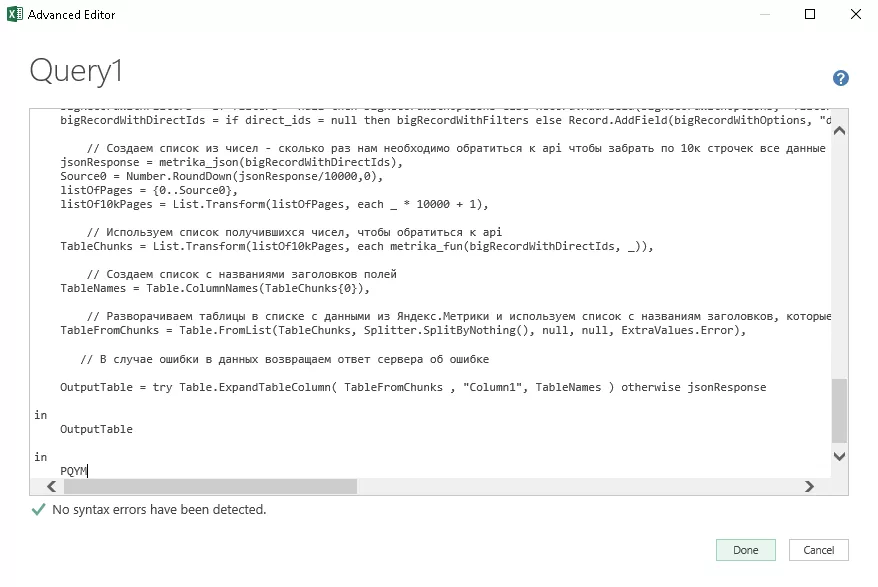
Скопировать код можно по ссылке. Автор кода Максим Уваров, благодарим его!
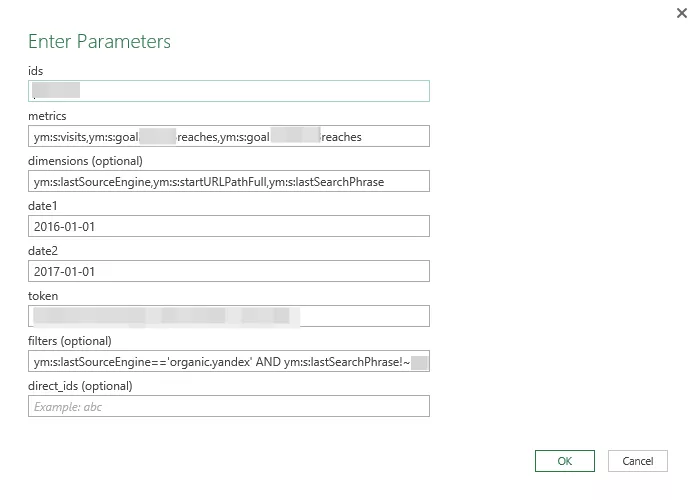
Вставляем параметры запроса
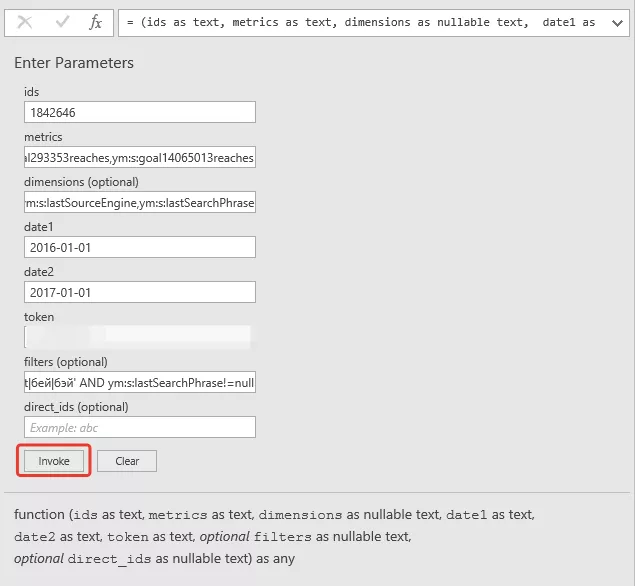
Подробнее о полях:
Если вы хотите составить свой собственный отчет, назначить фильтры, то вам потребуется ознакомиться с документацией API Метрики
В нашем запросе мы использовали следующие параметры:
# метрики количества визитов и количества достижения цели, вместо ХХХХ ID цели
metrics = ym:s:visits,ym:s:goaXXXXreaches
# параметры источника, страницы входа и поисковый запрос
demensions = ym:s:lastSourceEngine,ym:s:startURLPathFull,ym:s:lastSearchPhrase
# фильтры на органический трафик и исключение брендовых запросов через регулярное выражение
filter = ym:s:lastSourceEngine=='organic.yandex' AND ym:s:lastSearchPhrase!~'брендовыйЗапрос1|брендовыйЗапрос2' AND ym:s:lastSearchPhrase!=null
После нажатия Invoke вы увидите превью ваших данных. Если при запросе вышла ошибка, то можем редактировать запрос нажав на шестеренку Source
Если все хорошо, то нажимаем Close and load и загружаем все данные в таблицу.
Яндекс для нас является основным источником трафика, поэтому из Google поиск в рамках статьи рассматривать не будем, чтобы не усложнять
Нормализация, это приведение всех слов в единственное число именительный падеж и т.д. Для этого используем сервис K50
Копируем данные из файла lemmas.csv в наш основной файл во вкладку Lemmas. С помощью функции vlookup (в русском Excel ВПР) подтягиваем лемматизированные значения ключевых слов из таблицы lemmas.
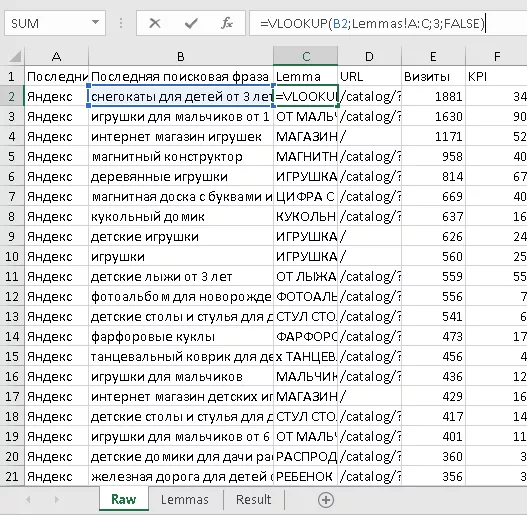
Все, задача выполнена!
Теперь у нас есть лемматизированный список фраз и нам нужно его очистить от фраз, которые не удовлетворяют требования Яндекс Директ. Для этого добавляем все фразы в Key Collector и нажимаем на иконку фильтра в столбике «Фраза»
Яндекс Директ не принимает в качестве фраз слова с составом более 7 слов и фразы со специальными символами, поэтому удаляем их.
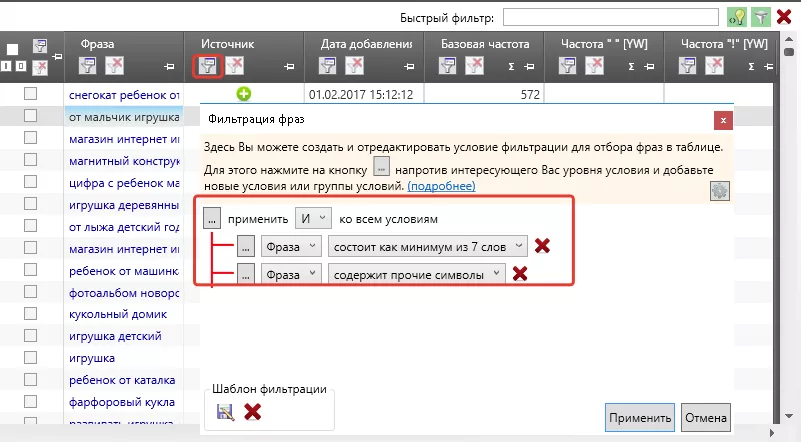
Далее фильтруем слова через список стоп-слов, то есть удаляем из нашего списка фразы, которые содержат стоп-слова.
Вебинар: как выжать максимум из контекстной рекламы
30-минутная выжимка нашего опыта на основе 100+ аудитов. Рассказываем, какие 12 ошибок чаще всего допускают предприниматели, когда начинают работать с контекстной рекламой.
Получить вебинар

Согласно свойствам аукциона Яндекс Директ и Google Adwords, для максимизации прибыли нам необходимо в качестве ставки установить ценность клика ключевого слова
Ценность клика = Средний чек * Доля маржи в чеке * Конверсия сайтаЕсть еще портфельная теория назначения ставок, она позволяет поднять прибыль на 10-20%, но в рамках статьи ее не рассматриваем, чтобы не усложнять.
Что это для нас значит? — Нам нужно собрать исторические данные конверсии и среднего чека в разрезе URL сайта и ключевых фраз. Эти данные мы будем использовать для назначения ставок.
Не можете состыковать, что к чему? Да, это сложновато, но вы все поймете, когда мы в финальной статье соединим все данные в одной формуле. Поэтому обо всем по порядку.
Сначала соберем средние чеки и конверсию по всем URL сайта, это просто. Эти данные мы можем взять из истории Google Analytics. Для этого понадобится Google Spread Sheets и Аддон Google Analytics, который вы можете установить в магазине дополнений.
Создаем новый отчет
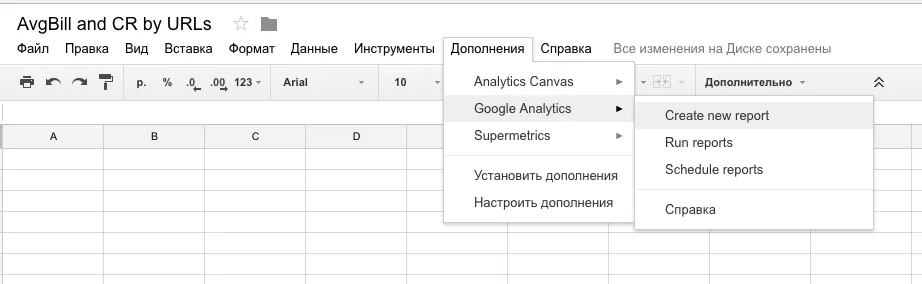
Вводим test, выбираем свой счетчик и представление Google Analytic, и нажимаем «Create report»
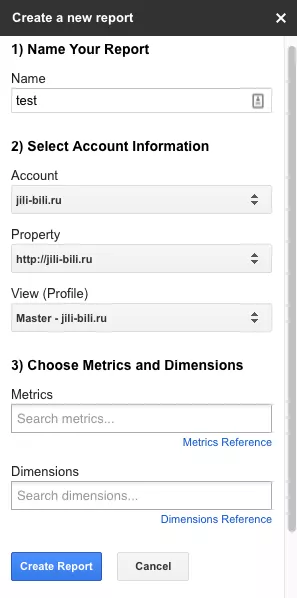
Вводим конфигурацию отчетов, как на картинке, и нажимаем Run reports. Понимаю, что пояснений к заданными параметрам недостаточно, но это может слишком далеко отвести нас от темы статьи. Подробную информацию вы сможете найти в документации
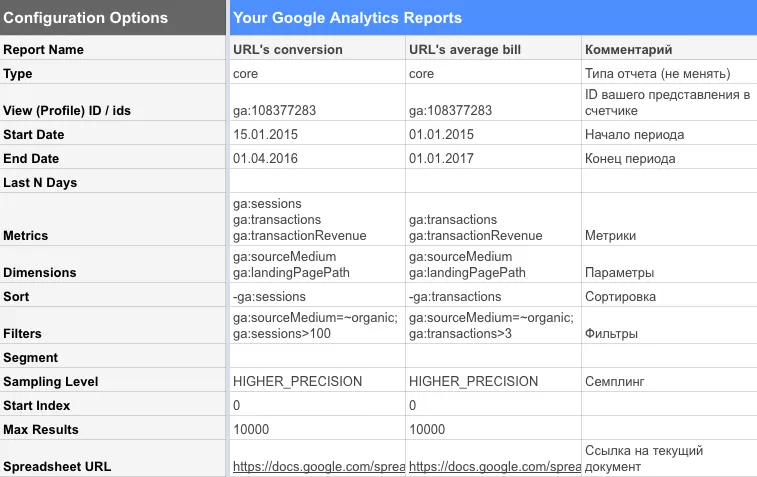
В нашем запросе мы использовали следующие метрики и параметры:
ga:sessions — количество визитов
ga:transactions — количество транзакций
ga:transactionRevenue — выручка
ga:sourceMedium — канал привлечения
ga:landingPagePath — страница входа
Теперь копируем отчеты на новые вкладки и вставляем только значения. Теперь нам нужно изменить точки на запятые, чтобы потом открыть документ в Excel - меняем.
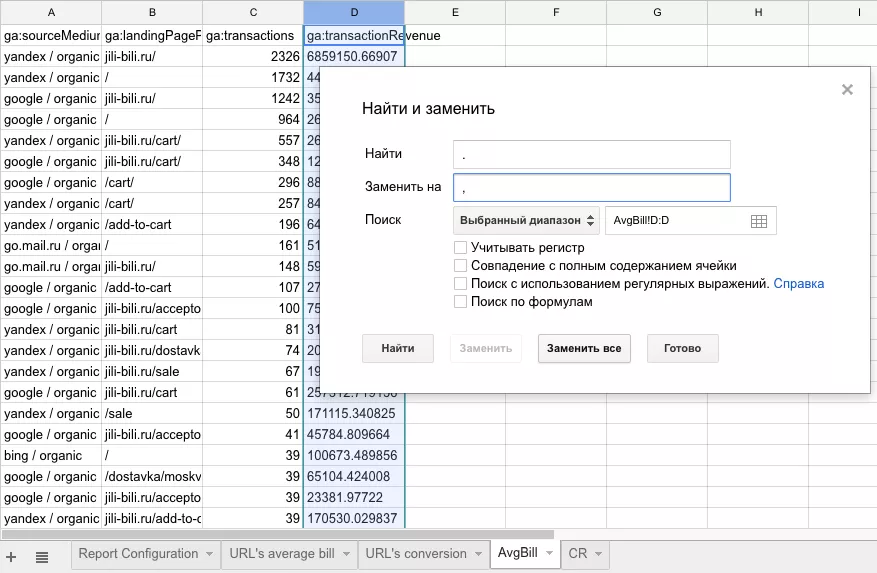
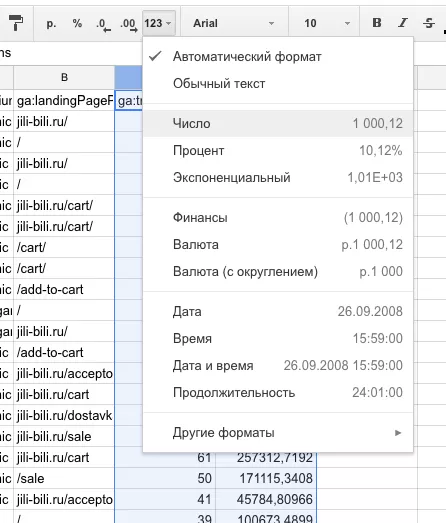
Для числовых значений задаем числовой формат.
Так как параметр ga:sourceMedium дублирует некоторые URL, то строим сводную таблицу. Попутно чистим от нежелательных значений и дублей.
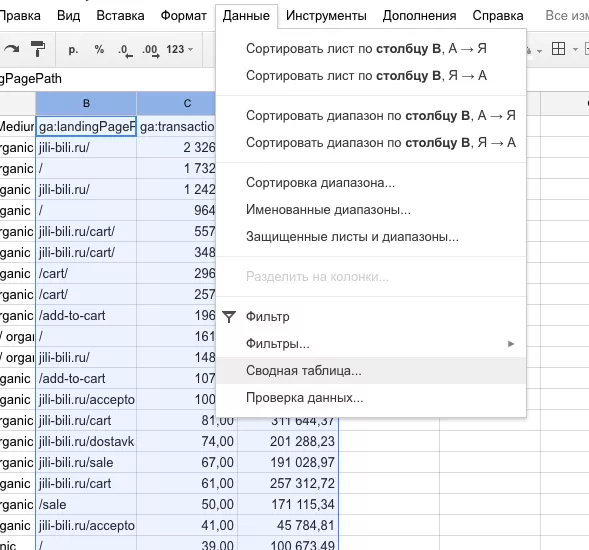
Добавляем новое рассчитываемое поле = 'ga:transactionRevenue' / 'ga:transactions' , это средний чек.
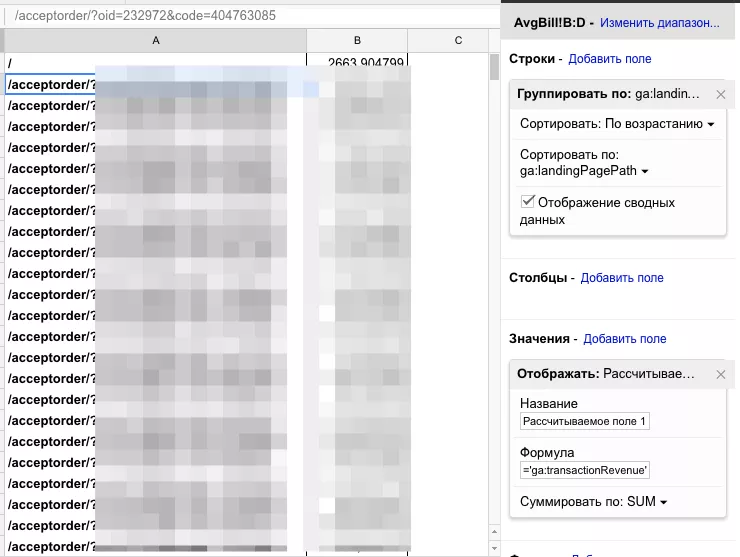
Ны выходе имеем аккуратную таблицу с URL и средними чеками.

Аналогичные операции проводим и с таблицей конверсии по URL.
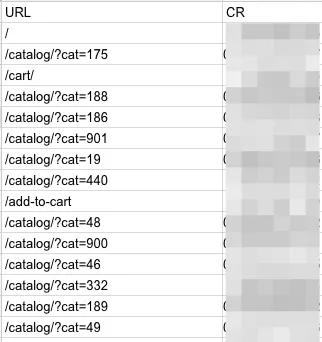
Весь документ можно скачать в Excel.
Выгружаем из Google Analytics, как мы делали несколькими шагами ранее. На скрине пример конфигурации отчета. В поле Filters мы используем регулярные выражения.
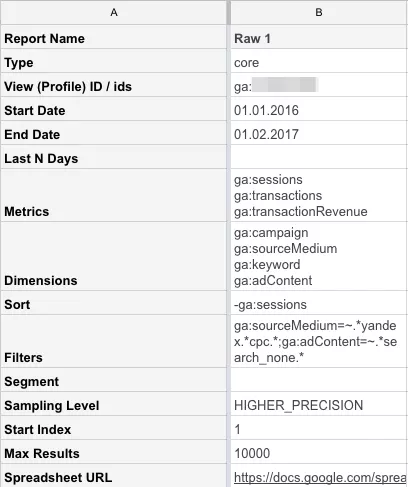
ga:adContent=~.*search_none.* — отфильтровываем только клики с поиска, исключая РСЯ; при условии, что у вас есть соответствующий параметр в UTM-метке
Start Index — начальная строка отчет
Max Results — последняя строка отчета
Дело в том, что отчет имеет ограничение в 10 000 строк, если у вас больше данных, то вы вызываете один и тот же отчет несколько раз и меняете Start Index и Max Results на 10001 и 20000 и так далее.
На выходе получаем следующее
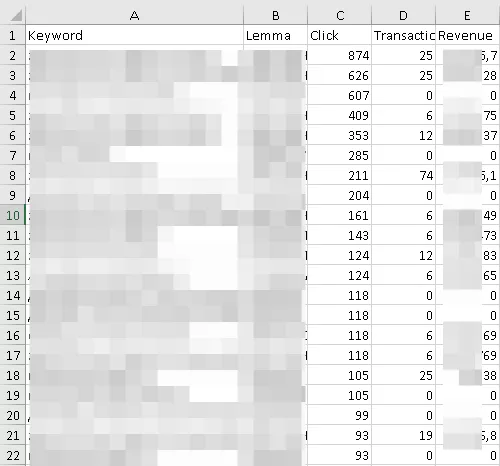
Все, мы собрали данные, с которыми будем работать в последующих этапах.
Пишите вопросы в комментариях, какие темы было бы интересно раскрыть подробнее? Если у вас есть идеи или советы, то делитесь!



После того, как вы оставите заявку: интервью ~15 минут → гостевые доступы для аудита ~15 минут → аудит в течение недели → согласование предложения → начало первой итерации. По нашему опыту реально начать что-то делать уже через неделю.

Менеджер проектов